자바스크립트
자바스크립트의 가비지 컬렉터 동작 방식
mark-sweep 방식으로 동작한다.
전역 객체, 함수 같은 객체 셋을 root 로 놓고
root 로 부터 객체를 탐색한다.
탐색하면서 00 , 10, 11 (흰색, 회색, 검은색) 으로 플래그를 나눠서 객체를 마킹한다.
흰색은 아직 탐색하지 않은 것이다.
회색은 marking worklist 에 들어간 상태이다.
검은색은 객체의 필드를 모두 탐색한 상태이다.
이렇게 처리하는 과정은 회색 객체가 없을때까지 한다.
이후 흰색 객체는 모두 반환된다.자바스크립트 가비지 컬렉터의 발전 과정
stop the world -> incremental -> parallel -> concurrent 형태로 발전해왔다.
stop the world 는 GC 동작시 프로그램이 멈춘다.
incremental 은 작은 단위로 나눠서 작업한다.
처리 량이 줄어 들 수 있다. -> 워커 스레드를 도입하면 이것을 해결 할 수 있다.
워커 스레드를 도입한 parallel 은 stop the world 방식을 멀티 스레드로 했다.
스레드 safe 하게 처리한다.
concurrent 방식은 워커 스레드와 bailout worklist 를 활용해서 처리한다.concurrent 가비지 컬렉터의 동작 방식
- 메인스레드가 marking worklist 를 만든다.
- 워커 쓰레드가 동시 마킹 작업을 돕는다.
- 워커 쓰레드가 bailout worklist에 객체를 넣는다.
- 메인 스레드는 js 애플리케이션을 실행하면서 때때로 bailout list와 marking worklist 를 처리한다.
- marking worklist 가 비게되면 메인스레드가 가비지 컬렉션을 끝낸다.
워커 쓰레드는 bailout worklist에 히든클래스, weak collection, 최적화된 코드객체 같은 것들을 넣는다.
히든클래스만해도 안 넣고 워커쓰레드들이 직접 가는건 동기화 작업도 필요하고 복잡해진다.
bailout worklist가 메인스레드 입장에서는 객체를 처리할때 쓰는 큐 같은 역할을 한다.
프로토 타입
프로토타입의 장점
프로토 타입을 사용하면 메모리 낭비를 줄일 수 있다.
function A() { this.name = 'hello',this.hi = 'hello' }
const 김 = new A();
const 이 = new A();
const 박 = new A();
console.log(김) // {name ='hello'} 출력- 이렇게 계속 new A(); 해서 선언하면 객체 1개당 메모리 2개씩 계속 차지한다.
- 프로토 타입을 쓰면 저 객체들을 만드는 함수 A의 프로토 타입에만 값을 정의해서 낭비를 줄일 수 있다.
A.prototype.name = 'hello'; // 이렇게 하면 된다.프로토 타입의 역할
- 자바스크립트 함수 객체의 생성자 정보와 자신을 만든 객체에 대한 정보를 갖고 있다.
- 생성자 정보는(Prototype object)
- 조상 객체에 대한 정보는 Prototype Link(proto)
프로토타입의 단점
- 프로토 타입은 JSON.stringify 에서 쓸 수 없다.
프로토타입 체이닝
- 프로토 타입 체이닝은 자바스크립트에서 객체가 proto 프로토 타입 링크를 통해서 상위 객체를 탐색하는 것을 말한다.
- 현재 자신을 생성한 prototype Object 에 찾는 값이 있는지 확인한다.
- 값이 없다면 Object 객체까지 탐색한다. 이렇게 Object 객체에 도달해도 값이 없을때 undefined 로 표시된다.
- 연쇄적으로 Object 객체까지 탐색하는 것을 프로토타입 체인 이라고 부른다.
url 모듈
node js 의 url 모듈은 웹 주소를 읽기 쉽게 파싱해주는 라이브러리다
var url = require('url');
var adrs = '<a href="http://localhost:8082/default.htm?year=2019&month=april">http://localhost:8082/default.htm?year=2019&month=april</a>';
var q = url.parse(adr, true);
console.log(q.host); //returns 'localhost:8082'eslint 설명
자바스크립트 구문 에러 탐지
nodejs Child process
싱글스레드인 nodejs 에서 멀티 스레드의 이점을 얻을 수 있다.
child process 모듈을 nodejs 에서 자식 프로세스를 만든다.
커맨드 명령어를 실행하는 spawn, exec 차이
spawn 과 exec는 자식 프로세스를 실행한다.
두 메소드의 차이는 spawn은 스트림을 리턴한다.
exec는 버퍼를 리턴한다.
spawn 은 큰 사이즈의 버퍼를 처리 할 때 쓴다.
exec는 커맨드를 실행하고 간단한 상태메세지를 받을 때 쓴다.
- require('child_process').fork()
fork 명령은 spawn 과 같은 역할을 한다.
Event Emitter
Event Emitter는 이벤트를 방출할 수 있는 모든 객체를 포함하는 nodejs 클래스다.
EventEmitter 를 사용하면 코드상에서 이벤트를 발생 시킬 수 있다.
그리고 그 이벤트가 발생할 때 처리하는 코드를 작성해둘 수 있다.
아래 예제 처럼 작성하면 myEmitter.emit('이벤트 이름') 하면 emitter.on('',() => {}) 에 작성된 콜백 함수가 동작한다.
ChildProcess도 EventEmitter의 객체이다.
const EventEmitter = require('events');
class MyEmitter extends EventEmitter { }
const myEmitter = new MyEmitter();
myEmitter.on('event', () => {
console.log('an event occurred!');
});
setInterval(() => {
myEmitter.emit('event');
}, 10);
// myEmitter.emit('event');
// other code
// ...
// myEmitter.emit('event');nodejs OLOO vs OO 패턴 차이
Constructor Form:
function Foo() {}
Foo.prototype.y = 11;
function Bar() {}
Bar.prototype = Object.create(Foo.prototype);
Bar.prototype.z = 31;
var x = new Bar();
x.y + x.z; // 42
OLOO Form:
var FooObj = { y: 11 };
var BarObj = Object.create(FooObj);
BarObj.z = 31;
var x = Object.create(BarObj);
x.y + x.z; // 42nodejs assert
테스트 작성시 사용한다.
node js의 디버깅
내장되어 있다. 디버그 모드로 실행 할 수 있다.
node debug [script.js | -e "script" | :] 로 실행하면 된다.
hidden 클래스
자바스크립트에서는 dictionary 형태의 데이터 구조에서 속성 값을 찾는게 java 같은 컴파일 언어보다 느리다.
그래서 이걸 극복하려고 hidden class 라는 것을 사용한다.
new 하고 객체를 생성할때는 initial 히든 클래스가 생긴다.
그리고 객체에 새로운 필드가 추가될 때 히든클레스가 새롭게 생성된다.
객체는 새로 생성된 히든 클래스를 참조한다.
이전의 히든 클래스는 새로운 히든 클래스를 참조한다.
V8은 히든 클래스를 이용하여 동적 탐색(Dynamic Lookup)을 회피한다.
한마디로 프로퍼티가 바뀔 때 각각 그 프로퍼티의 오프셋을 업데이트한 뒤 그 값을 가지고 있는 방식.
- java 같은 클래스 기반의 컴파일 언어에서는 모든 객체가 같은 필드를 갖는다.
- 자바스크립트에서는 const a = new A(), const b = new A() 해놓고 a에는 name 을 추가하고 b에는 추가 안 할 수 있다.
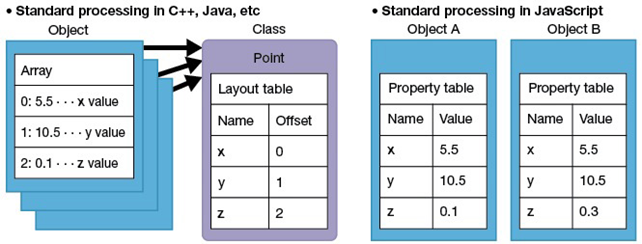
이런 구조로 되어있는데 모든 객체가 모든 필드를 다 들고 있다.
이러면 메모리 낭비도 많고 성능에 좋지 않다.
그래서 hidden 클래스, 인라인 캐싱 같은 것을 사용헌다.
엔진 내부적으로 클래스를 두는 방법이다.
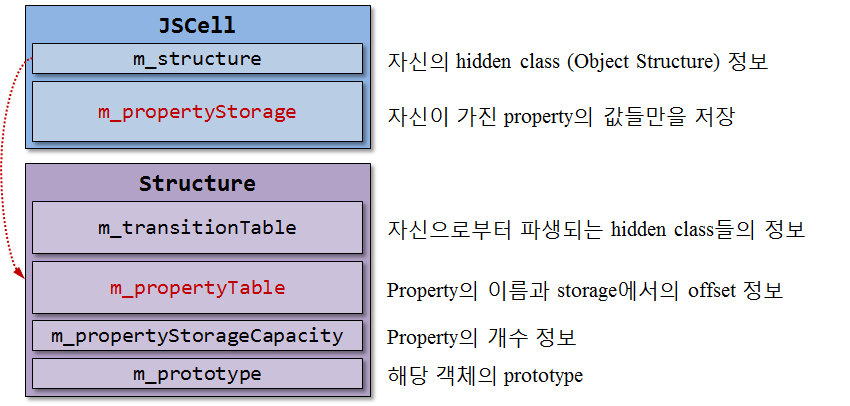
- nhn 블로그 그림
직접 확인해본 히든 클래스

히든 클래스는 크롬 개발자 도구에서 확인 할 수 있다.
Map 으로 적혀있는 부분이 히든클래스이다.
인라인 캐싱
인라인 캐싱은 히든 클래스를 기반으로 한 최적화 방법이다.
히든 클래스에 있는 접근하려는 필드의 오프셋 값을 캐싱한다.
동일한 유형의 객체가 동일한 히든 클래스를 공유한다.
for (var i=0; i<10; i++) {
arr[i].x = i;
}이런 코드의 경우에 인라인 캐싱이 일어난다.
i의 첫번째 경우에는 x 값을 일반적으로 탐색한다.
다음 스텝부터는 arr[0]의 structure와 arr[0].x의 오프셋 값이 캐싱됩니다.
그래서 다음 스텝부터는 더 빠른 탐색이 가능합니다.
이런 기능은 arr[0]부터 arr[9]까지 모두 같은 필드 구조를 갖고 있을때 쓸 수 있는 기능입니다.
만약에 0부터 9까지 구조가 다양하고 다르다면 인라인 캐싱이 안됩니다.
javascript WeakMap
객체를 키로 가질 수 있는 자료형
const o1 = {}
b.set(o1,20)
b.get(o1)
20express
express 앱에서 www와 app.js 가 분리되어 있는 이유
- 네트워크 호출을 수행하지 않고 api를 테스트 할 수 있다.
- 항상 같게 api를 실행 할 수 있다.
timer 함수
set timeout 함수
- 지정한 밀리초 이후 코드 실행을 스케줄링 할 수 있다.
setInterval 함수
- 지정 시간 단위로 무한 반복 실행한다.
set immediate 함수
- setImmediate 함수는 현재 이벤트 루프 주기 끝에 코드를 실행한다.
- 현재 이벤트 루프의 모든 io 작업 후에 다음 이벤트 루프에 스케줄링된 모든 타이머 이전에 실행된다.
- Immediate 객체를 반환한다.
process.nextTick 함수
- 이벤트 루프의 현재 단계와 관계없이 현재 작업이 완료된 후에 처리된다.
- 여기서 말하는 작업은 실행되어야 하는 javascript 처리
process.nextTick()은 Event loop의 일부가 아니며, nextTickQueue는 현재 진행 중인 작업(C/C++에서의 전환, 실행되어야 하는 자바스크립트 처리)이 끝나면 실행된다고 나와있습니다.-
process.nextTick 을 재귀적으로 호출한다면 문제가 된다.
- 이벤트 루프를 진행하기 전에 처리되기 때문이다.
- 재귀적으로 호출하면 이벤트 루프가 poll 단계로 가는 것을 막는다.
- -> API는 비동기로 설계 되어야 한다는 철학때문에 그렇다.
-
이름은 setImmediate가 더 즉시 실행같다.
-
하지만 process.nextTick이 먼저 실행된다.
수많은 npm 패키지가 이대로 개발되었기 때문에 이름이 바뀔 일은 없다.
setImmediate 가 이름이 더 직관적이므로 setImmediate 를 쓰는 걸 권장한다.
process.nextTick 쓰는 이유
- 이벤트 루프를 계속 하기 전에 오류처리/불필요한 자원 정리를하고 요청을 다시 시도 할 수 있게 한다.
- 만약 비동기 코드를 사용자의 기대에 맞춰서 이벤트 루프를 계속 진행하기 전에 실행할때 쓸 수 있다.
Promise, process.nextTick, setTimout, setImmediate 실행 순서
- process.nextTick 제일 먼저
- Promise
- setTimeout, setImmediate 는 호출 순서대로
- 만약 setTimeout에 ms를 크게 준다면 ()=>{console.log()} 했을 때 setImmediate가 먼저 나오기도 한다.
- setInterval도 코드에 있으면 setInterval은 나중에 실행됨
메모리 관리
javascript 메모리 누수 현상에 대해서 설명
-
발생 원인 : CPU 인텐시브한 작업이 callstack 에서 실행되고 있는 상황에서
메모리 사용량이 증가한다. 이때 메인 스레드가 GC 할 틈이 없다면 메모리 누수가 발생한다. -
해결 / 예방 방안
- setTimeout, process.nextTick 을 활용해서 callstack 말고 node api 에서 작업을 처리하도록 한다.
- GC 가 처리할 틈을 만들어준다.
- 클로저와 스택의 빈번한 사용을 자제한다.
- GC를 수동으로 이벤트 루프에 넣을 수도 있겠지만 그렇게 하면 성능이 저하된다.
- setTimeout, process.nextTick 을 활용해서 callstack 말고 node api 에서 작업을 처리하도록 한다.
-
메모리 누수를 탐지하는 방법
- heapdump npm 모듈을 설치하고 탐지할 수 있다.
변수, 타입
변수 호이스팅
자바스크립트 코드를 읽고 실행할때 변수가 유효범위의 최상단으로 끌어 올려진다.
var 로 선언한 변수, 함수에 대해서 일어난다.
let, const 에서는 호이스팅이 일어나지 않는다.
자바스크립트의 primitive 타입 종류
- number
- string
- object
- null
- undefined
- Symbol - es6에서 추가됨
- boolean
- null은 typeof null === 'object' 하면 true가 나온다.
null은 object 의 하위타입이면서 코드상에서는 false 값처럼 다뤄진다.
javascript native 타입 종류
- String
- Number
- Boolean
- Array
- Object
- Function
- RegExp
- Date
- Error
- Symbol
new 를 통해서 사용 할 수 있다ㅏ. 굳이 new 를 안 적어줘도 된다.
java 쪽의 래퍼 클래스(Integer) 이런 것들과 비슷하다.
javascript 에서는 함수와 비슷하다. - javascript 에서는 함수가 객체
값은 valueOf 로 얻으면 된다. object 이기 때문에 toString() 같은 Object 객체의 함수들을 쓸 수 있다.
자바스크립트에서는 이런 변환이 자동으로 되기 때문에 굳이 사용자가 하지 않아도 된다.
const a = 'name';
a.length;
a.toString()javascript Symbol
Symbol 은 es6에서 추가된 primitive 타입이다.
객체의 key를 추가할때 쓸 수 있다.
- symbol을 통해서 추가한 key 값은 JSON.stringify에서는 나오지 않는다.
- symbol을 통해서 추가한 key 값은 Object.keys에서도 안나온다.
- for-of에서도 안나온다.
cosnt a = {}
const symbolProperty = Symbol('key');
a[symbolProperty] = 'hello';
console.log(a); // { Symbol('key'): 'name' }javascript typeof instanceof 차이
typeof는 연산자로써 해당 타입이 맞는지 검사한다.
인자를 하나만 받을 수 있는 연산자
instanceof 는 비교연산자이다. 인스턴스인지 검사하고 true, false를 리턴한다.
undefined 를 에러없이 검사하는 방법
typeof 를 사용한다.
typeof a 히고 정의되지 않은 변수를 typeof하면 undefined가 나온다.Object method 정리
- Object.keys
객체 안에 있는 키들을 탐색 할 수 있다.
Object.keys((key) => {
});-
Object.assign(target, source)
객체를 복사한다.const a = {a: 1, b:2 } const b = {c :3, d:4 } const c = Object.assign(a, b); console.log(c); // {a: 1, b:2, c:4, d: 4}source 를 target에 복사해서 넣는다.
-
Object.is(value1, value2)
Object.is(1, 1) // true두 값이 같은 값인지 비교한다.
Array.from()
console.log(Array.from('foo'));
// expected output: Array ["f", "o", "o"]
console.log(Array.from([1, 2, 3], x => x + x));
// expected output: Array [2, 4, 6]function 은 typeof === function 하면 true 가 나오는데 function 타입은 없나요?
없다. 자바스크립트에서는 function 은 object 의 일부이다.
javascript 클로저
독립적인 변수를 가리키는 함수이다.
함수가 생성된 환경을 기억한다.
const func = () => {
const name = 'name';
return () => {
console.log(name);
}
}
const v = func();
v(); // name 출력libuv
libuv api 설명
- 1줄 설명: nodejs 에서 비동기 작업을 수행하기위해서 쓰는 c++ 로 개발된 비동기 api
os 커널의 비동기 인터페이스를 활용한다.
libuv 동작 방식
- 각 os 커널의 비동기 io 를 이용한다.
- 리눅스의 경우에는 AIO 를 이용한다.
운영체제의 비동기 이벤트는 libuv의 이벤트로 취급된다.
- ex) 파일 쓰기가 끝났다고 하면 libuv 까지 전달되고 이벤트 루프에 콜백이 등록된다.
요약
- node 인스턴스가 실행될때 libuv에 워커 스레드 풀(4개)가 생성된다.
- io 작업이 들어오면 이벤트 루프가 libuv로 보낸다.
- libuv는 os 에서 제공되는 비동기 작업들이 어떤것인지 알고 있다.
- os 커널의 비동기 함수들을 호출한다.
- 작업이 완료되면 이벤트 루프의 콜백으로 간다.
- 만약 os 커널에서 제공되지 않는 비동기 작업이라면 libuv의 워커쓰레드가 수행한다.
libuv 를 쓰는 것의 장점
libuv는 windows, linux 플랫폼의 비동기 io 인터페이스를 추상화시켰다.
libuv는 플랫폼 독립적이다. 각 플랫폼의 비동기 io 인터페이스를 활용 할 수 있다.
libuv 기능 몇가지
- 파일 시스템, 이벤트
- 스레드 풀
- 비동기 TCP, UDP 소켓
libuv api 는 비동기 api로써 os 커널의 비동기 인터페이스를 쓰다가 안될때
디폴트 크기 4의 스레드 풀을 할당하고 비동기 처리를 돕는다.
libuv 그림

- 그림 http://docs.libuv.org/en/v1.x/design.html
nodejs 에서의 libuv의 역할
nodejs 에서 io 작업을 담당한다.
- 기본적 스레드 풀의 스레드 개수는 4개다.
os 커널에서 제공하는 비동기를 활용하고 커널에서 제공되지 않는 것은 libuv의 스레드 풀로 처리한다.
덧붙여서 스레드 개수는 코어의 개수와 동일할때가 최적이다.
운영체제 커널에서 제공해주는 비동기 인터페이스 예시
리눅스 - AIO 가 있다.
Asynchronous IO
기존의 전통적인 IO 모델에서는 단일한 핸들로 식별되는 하나의 블로킹 IO가 있었고
이를 파일 설명자(descriptor)로 불렀으며 이들이 파일, 파이프, 소켓 등등에 모두 적용되었다.
사용자는 하나의 전달(transfer)을 하고 시스템 콜이 그에 대한 리턴을 해줬다.
이제 AIO에서는 복수의 전달을 할 수 있다. 이를 위해 각각의 전달들을 식별하기 위한 식별자가 필요하고, 이것이 AIOCB(AIO Control Block) 구조체로 구현된다.
AIOCB(AIO Control Block))는 전달에 관한 모든 정보를 담고 있고, 데이터에 관한 사용자 버퍼까지 포함하고 있다.
한 IO에서 알림이 발생하면(이를 완료(completion)라 부른다), 이를 유일하게 식별하기 위해 AIOCB 구조체가 준비된다.
struct aiocb {
int aio_fildes; // 파일 설명자(descriptor)
int aio_lio_opcode; // lio_listio 하고만 관계 있는 변수 (r/w/nop)
volatile void *aio_buf; // 데이터 버퍼
size_t aio_nbytes; // 데이터 버퍼 속 바이트 수
struct sigevent aio_sigevent; // 알림(notification) 구조체
/* Internal fields */
...
};스코프
스코프 체인에 대해서 아는대로 설명
자바스크립트 코드가 실행 될때 EC가 만들어진다.
Excution Context.
function a() {
const v = 1;
function b() {
console.log(v);
}
b();
}
a();이 코드에서는 v의 값인 1을 출력할 수 있다.
가장 상위에는 전역 스코프가 있다.
function a 가 호출되면서 a의 렉시컬 환경이 만들어진다.
a 의 렉시컬 환경은 전역 환경의 environment record 를 가리킨다.
b가 호출되면서 b의 렉시컬 environment 는 a의 environment record 를 가리킨다.
함수가 자신의 영역에 해당 변수가 없을때 상위 환경에서 변수를 찾는다.
이렇게 연결된 것을 스코프 체인이라고 한다.
자바스크립트 스코프
-
어디서 어떻게 변수를 찾는지를 결정하는 규칙의 집합
-
스코프는 목표와 일치하는 대상을 찾으면 검색을 중단한다.
-
자바스크립트는 함수 기반 스코프를 사용한다.
try - catch if - else if 에서도 스코프는 있다.
스코프를 쓰는 이유
- 최소 권한 원칙에도 맞는다. - 최소 권한 원칙 = 필요한 것만 나타내고 나머지는 숨긴다.
렉시컬 스코프
- 자바스크립트 컴파일러는 토크나이징/렉싱 과정을 통해서 구문을 분석한다.
렉시컬 스코프는 이런 렉싱 과정에서 정의되는 스코프다.
=> 프로그래머가 코드를 작성할때 함수를 어디에 선언하는지에 따라 정의되는 스코프
** 렉시컬 스코프는 eval 을 통해서 수정할 수 있다. 하지만 성능 저하를 가져오므로 쓰지 않는다.
블록 스코프
try-catch, if-else if 처럼 블록으로 나뉜 스코프
javascript eval()
eval은 문자열을 받아서 실행 시점에 코드인것처럼 처리한다.
eval(var a = 2);이렇게 하면 var a = 2 가 코드로 작성된 것처럼 동작한다.
자바스크립트에서 클래스 상속은 내부적으로 어떻게 동작하나요
저버스크립트 내부적으로 클래스는 함수와 같은 형태로 동작한다.
Object 의 객체이다.
아래와 같이 class A {} , class B extends A {} 로 되어 있다고 해보자.
new B();이렇게 선언하고 proto 프로토 타입 링크를 타고 올라가면 A 의 프로토타입이 나온다.
A의 proto 를 확인하면 Object의 프로토타입이 나온다.
자바스크립트 this 키워드
- this는 일단 함수의 렉시컬 스코프를 참조하지 않는다.
아래 우선순위로 실행 시점에 바인딩 된다.
- new 로 호출한 경우 - 새로 생성한 객체로 바인딩
- call, apply 로 호출했으면 주어진 객체로 바인딩
- 함수 호출 컨텍스트를 읽고 바인딩
자바스크립트의 생성자
- 자바스크립트의 생성자는 클래스의 생성자와는 다르다.
new 가 붙었을때 호출되는 함수이다.
이벤트 루프 설명
- 1줄 설명 nodejs 에서 작업 흐름을 제어하는 루프이다.
- 여러 페이즈로 나눠져 있다. 무한루프를 돌면서 탐색을 반복한다.
- 단계마다 실행할 콜백의 FIFO 큐를 가진다.
- timer = set timeout , set interval 콜백이 실행된다.
- pending callback = 다음 루프 반복으로 연기된 io 콜백을 실행한다.
- idle, prepare
- poll => 여기서 대부분의 io 콜백 실행
- check = setImmediate 콜백은 여기서 호출
- close callback = 일부 close 콜백 ex) socket.on('close')
- call stack, node api(web api), task queue 사이에서 task queue 에 있는 콜백함수를 call stack 으로 가져온다.
- call stack 이 비어있고 task queue 에 콜백 함수가 있을때 가져온다.
- call stack이 비어있지 않다면 안 가져온다.

| Phase | 대상 | 처리 작업 |
|---|---|---|
| timer | setTimeout(func, delay), setInterval(func, delay) | delay가 지났으면 등록된 callback 실행 |
| poll | I/O | 대부분의 callback 실행 |
| check | setImmediate(func) | 등록된 callback 실행 |
timer
setTimeout 0을 했을때 일어나는 일
web api또는 node api가 setTimeout 작업을 처리한다.
작업을 처리하고 태스크 큐에 콜백함수가 들어간다.
그다음 call stack 이 비어있다면 콜백함수를 call stack 으로 가져간다. 실행한다.
setTimeout 3000 이 정확히 3초가 아닌 이유
api - 태스크 큐 - callstack 으로 이동하는 과정에서
call stack 에 함수가 있으면 태스크 큐에서 나오지 못한다.
태스크 큐에서 앞에 다른 콜백함수가 있으면 그 함수가 먼저 처리되어야 한다.
그래서 3초보다 더 걸린다.
setTimeout 0은 왜 쓸까
실행이 너무 오래 걸리는 코드를 다른 태스크로 나눠줄 수 있다.
loading()
takeLongTime()
hideLoading()
showResult()이렇게 하면 loading 함수가 동작하고 바로 오래걸리는 작업이 수행된다.
loading()
setTimeout(() => {
takeLongTime()
hideLoading()
showResult()
})이렇게 해주면 loading 이 callstack에서 실행되고
태스크 큐에서 콜백힘수를 하나씩 가져와서 실행 할 수 있다.
setTimeout 0이 정확히 0이 아닌이유
브라우저는 내부적으로 타이머의 최소 단위를 갖고 있다.
이것은 브라우저마다 다르다.
예를 들어서 크롬은 최소 단위가 4ms 이다.
그래서 크롬에서 setTimeout 0 을 하면 4ms 이후에 된다.
Promise 와 마이크로 태스크 큐
setTimeout(function() { // (A)
console.log('A');
}, 0);
Promise.resolve().then(function() { // (B)
console.log('B');
}).then(function() { // (C)
console.log('C');
});코드의 실행 순서는 B - C - A 이다. C 아래에 then 하고 console.log D가 또 있어도 똑같다.
B-C-D-A
Promise 는 마이크로 태스크를 사용한다.
마이크로 태스크 큐는 태스크 큐보다 우선순위가 높다.
이벤트 루프는 마이크로 태스크 큐를 먼저 검사하고 태스크 큐를 검사한다.
마이크로 태스크 큐에 있는 콜백함수를 먼저 call stack 으로 가져간다.
nodejs LTS 릴리즈 차이
LTS는 Long Term Support버전으로써 2년간 해당 버전에 대한 취약점, 개선 사항 패치를 보장한다는 것이다.
current 버전은 개발 진행중인 버전이다.
스트림
node js 스트림 동작 원리
-
스트림 : 배열, 문자열과 유사한 데이터의 컬렉션이다.
-
버퍼를 활용해서 동작한다.
-
기존 방식
read - compress - send -> receive - de compress - write
이 방식을 병렬로 작게 쪼개서 동작한다.
read - compress - send => receive - de compress - write
read - compress - send => receive - de compress - write여기서 데이터 청크에 대해서 순서는 보장되어야 한다.
스트림이 소비하는 것보다 더 빨리 데이터를 쓰면 병목현상이 발생한다. = 백프레셔
스트림의 장점
- 메모리를 적게 쓸 수 있다.
만약 스트림없이 400mb의 파일을 읽고 다루게 되면 메모리에 400mb가 그대로 사용된다.
스트림을 사용하면 400mb -> 20mb 정도로 사용을 줄일 수 있다.
백프레셔
스트림+버퍼를 활용해서 읽기 쓰기 작업을 할때 읽기 부분보다 쓰기 부분이 빨라서 병목 현상이 생기는 것을 말한다.
read 하는 중 write() 에서 데이터가 없다면 false 가 리턴된다.
데이터베이스
RDB와 Document DB 차이
-
rdb = 조인 연산을 할 수 있다. cascade delete 가 지원된다.
- 트랜잭션을 잘 지원한다.
-
document db = 조인 연산을 할 수 없다. cascade delete 가 안된다.
- 쓰기 연산 속도가 빠르다.
- 스키마가 매우 유동적인 경우 쓸 수 있다.
- 쌓아 놓는 용도로 쓰기 좋다.
데이터베이스 샤딩에 대해서 설명
- 데이터베이스에 다량의 데이터가 저장 될때 물리적인 저장 공간을 분할해서 저장하는 방식
자료구조
B 트리 설명
자식 노드의 개수가 2개 이상인 트리를 말한다.
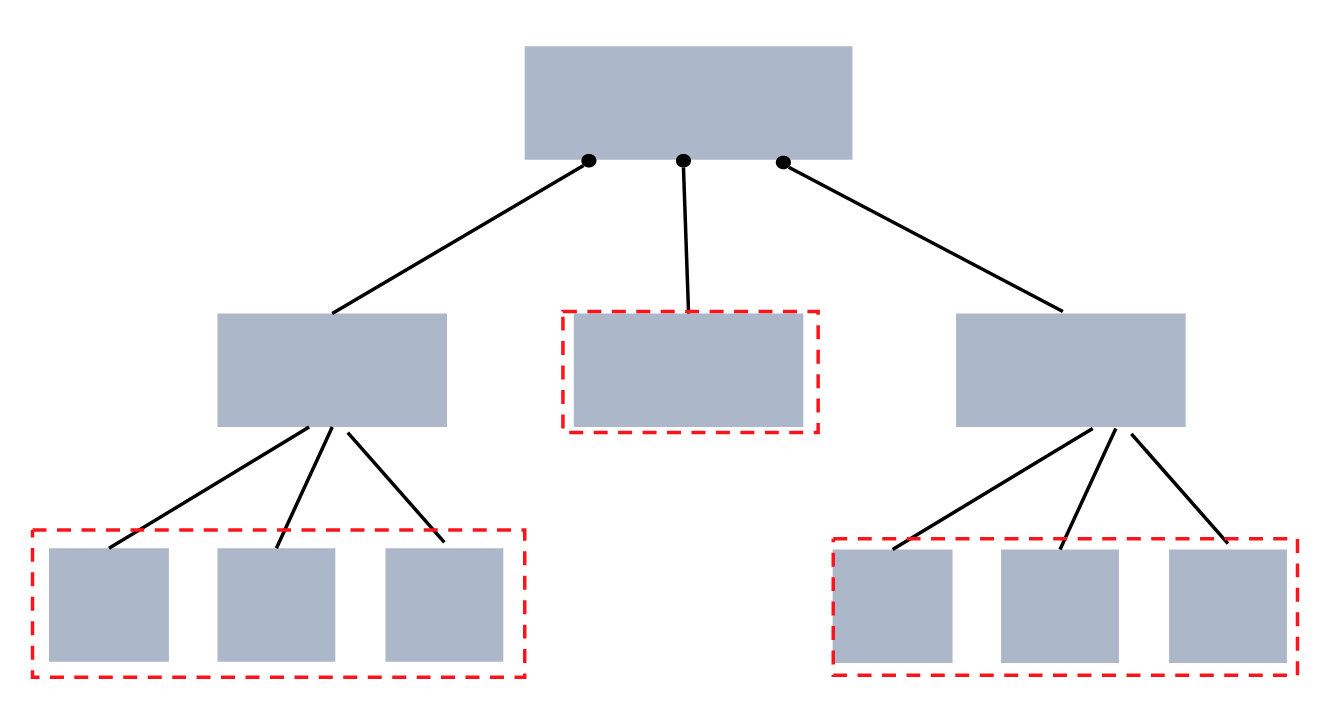
-
탐색 - 작은 값은 왼쪽 서브트리, 큰 값은 오른쪽 서브트리에 있다.
root 부터 탐색한다. -
삽입 - 데이터를 탐색하고 leaf 노드에 데이터를 삽입한다.
leaf노드에 데이터 개수가 차수만큼 가득하면 노드를 분리한다.
7,9,12=> 7- 왼쪽 , 9 가운데, 12 오른쪽 -
삭제 - 리프노드인 경우 - 리프 삭제후 삭제한 노드의 부모노드로 올라가며 데이터를 가져온다.
- 리프가 아닌 경우 노드에서 지우고 왼쪽 자식트리에서 최대값을 노드에 놓는다.
이진 트리
자식 노드가 최대 2개인 트리를 말한다.
리액트
리액트 useState, useEffect 설명
useState
- 함수형 컴포넌트에서 1개의 상태 값을 관리 할 때 쓸 수 있다.
- [state, setState]를 리턴한다.
setState 함수는 클로저 함수이다. state 값을 변경 할 수 있다.
useEffect
- 컴포넌트가 렌더링 될 때마다 특정 작업을 수행하도록 할 수 있다.
- 마운트 될 때만 실행하려면 빈 배열을 파라미터로 보낸다.
useEffect뒤에 있는 빈 배열의 의미
- useEffect 파라미터로 빈 배열을 보낸 경우
useEffect(() => {
}, []);
컴포넌트가 마운트/언마운트 되었을때 실행된다.- useEffect 파라미터로 특정 값이 들어있는 배열을 보낸 경우
useEffect(() => {
}, [name])
name 값이 변경되었을때 실행된다.
이런 형태를 사용하면 텍스트 박스에 값이 변경되었을때 api를 호출 할 수 있다. - 검색기능- useEffect 파라미터로 값을 안 보낸 경우
useEffect(() => {
})
이렇게 쓰면 모든 변경사항에 대해서 콜백함수가 실행된다.리액트 훅의 동작 방식
useState 함수를 통해서 클로저처럼 동작한다.
내부적으로는 hook이 배열처럼 되어있다.
setState 함수를 해서 훅을 만들면 1개의 인덱스를 차지하게 된다.
setState 함수는 배열 형태의 값을 리턴한다. [value, setValue]
리액트 훅을 조건문, 반복문과 쓸 수 없는 이유
조건 문이나 반복문에서 쓰게 되면 인덱스의 순서를 보장 할 수 없게 된다.
상태 관리도 보장 할 수 없게 된다.
리액트 리덕스 동작 방식
- 리덕스는 컴포넌트간의 상태를 공유하기 위해서 사용한다.
- a - b- c - d - e 의 5단계로 컴포넌트가 계층 구조를 가질때
- a 에서 e로 5단계에 걸쳐서 prop 값을 전달하는 것은 불편하다.
리덕스를 사용하면 값을 리덕스 스토어 저장하고 5개의 컴포넌트가 값을 공유할 수 있다.
컴포넌트 x 는 리듀서를 사용해서 리덕스 스토어에 있는 값을 수정한다.
컴포넌트 y는 리덕스 스토어를 구독하고 함수를 전달한다.
값에 변화가 생기면 이 함수를 호출한다.
리액트 prop과 state
-
prop 은 부모 컴포넌트에서 자식 컴포넌트로 보내는 값이다.
- prop 을 자식 컴포넌트에서 변경 하는 경우는 없다.
- 코드상으로 자식컴포넌트에서 부모 컴포넌트로 값을 보낼 수는 있다. 보통 그렇게 하지 않는다.
-
state 는 컴포넌트 내부에 존재한다.
- 컴포넌트 안에서 변경되는 값을 다룰 때 사용한다.
웹 사이트 프론트가 느릴때 최적화 방법
-
현재 로딩 시간을 측정하는 방법
- 크롬 개발자 도구에서 network 네트워크 대역폭 제한 체크
- 캐시 비활성화
- 페이지 새로고침
-
자바스크립트의 용량을 줄여서 빨리 불러오도록 하는 방법이 있다.
-
webpack-bundle-analyzer 모듈을 써서 번들 크기에 어떤게 많은 비중을 차지하나 본다.
localhost:8888 접속한다. -
이미지 로딩 부분 수정
- 사이트에서 화면에 잡히지 않은 이미지까지 전부 로딩하지 말고
- 화면에 잡힐때 이미지를 로딩하도록 수정
-
렌더링 개선
- 우선 순위가 낮은 작업을 콜백 함수로 전달해
- 브라우저 메인 스레드가 한가해지는 시점(idle 상태)에 호출합니다.
서버 사이드 렌더링, 클라이언트 사이드 렌더링
-
서버 사이드 렌더링
- 서버에서 html 을 내려주는 방식
- 초기 로딩 속도가 빠르다.
- 남용하면 서버에 부하가 크게 걸린다.
- 간단한 수정도 모두 서버를 거쳐야 한다.
-
클라이언트 사이드 렌더링
- 클라이언트 사이드에서 자바스크립트를 사용해서 렌더링 하는 방식
- 초기 로딩 속도는 비교적 느리다.
- 검색엔진 최적화 문제가 있을 수 있다.
- index.html 파일은 비어있는 파일이기 때문에 검색엔진에서 검색되지 않을 수 있다.
- 구글은 자바스크립트를 분석해서 크롤링하기 때문에 검색이 된다.
css, scss
SASS는 CSS를 만들어주는 언어로
Javascript처럼 특정 속성(ex. color, margin..)의 값(ex. #000, 3px...)을 변수로 선언하여
필요한 곳에 선언된 변수를 적용할 수도 있고,
반복되는 코드를 한번의 선언으로 여러 곳에서 재사용할 수 있도록 도와주는 기능을 가졌다. MSA
MSA 통신에서 보안처리
- 인증 = 내가 유저가 맞다.
- 인가 = 내가 이 권한이 있다.
-
일단 허용하기
-
https 기본 인증
- 이름, password 를 http 헤더에 넣어서 전송한다.
- 서버는 상세 내용을 확인하고 접근 여부를 승인한다.
- 이때 https로 통신한다.
-
saml, openid connect
모든 서비스의 접근 통제를 중앙의 디렉토리 서버를 쓴다. -
클라이언트 인증서
- 클라이언트 측의 인증서를 가지고 통신한다.
- 공개키 기반의 인증서를 쓴다.
- hmac 방식
Hash Based Message Code
요청 메세지 바디가 비밀키로 해시된다.
해시 결과를 전송한다.- 스누핑 당할 수 있다.
현재의 권장사항 - open connect / aws vpn 활용하기
같은 네트워크 망 안에서만 접속할 수 있도록 할 수 있다.
OWASP 10 = 웹 취약점 top 10
-
인젝션 = SQL 인젝션 같은 것을 말한다.
시스템에 신뢰할 수 없는 데이터나 쿼리를 보낸다. -
취약한 인증
인증, 세션관리 기능이 취약해서 공격자가 키, 토큰을 알아낼 수 있다. -
민감한 데이터 노출
통신시 금융정보, 개인 식별 정보가 노출되는 것 -
xml 외부 객체
xml 기반의 시스템에서 외부의 xml을 업로드 하거나 입력하는 것을 말한다. -
취약한 접근 통제
인가 기능이 취약해서 권한을 넘나들고 수정할 수 있는 것 -
잘못된 보안구성
공격자는 인가되지 않은 영역으로 접근할 수 있는 권한이나 시스템 정보를 얻기 위해 패치 되지 않은 취약점을 공격하거나 디폴트 계정, 미사용 페이지, 보호받지 못하는 파일이나 디렉토리에 접근을 시도한다. -
크로스 사이트 스크립팅
<script></script>를 주입해서 특정 페이지로 redirect 시키거나 세션을 탈취한다. -
안전하지 않은 역 직렬화
역직렬화 취약점은 원격 코드 실행으로 이어진다.
권한 상승 공격, 주입공격, 재생공격들에 활용될 수 있다.
- 알려진 취약점이 있는 구성요소 사용
라이브러리, 프레임워크는 애플리케이션과 같은 권한으로 실행된다.
취약한 구성요소를 쓰면 위험하다.
- 불충분한 로깅과 모니터링
불충분한 로깅과 모니터링은 공격자들이 시스템을 더 공격하고 더많은 시스템을 중심으로 공격할 수 있도록 한다.
CAP 이론
-
Consistency - 일관성 = 모든 노드들은 같은 항목에 대해서 같은 데이터를 보여준다.
-
Availability - 가용성 = 모든 사용자들은 읽기 쓰기가 가능해야 한다. 몇몇 노드의 장애가 다른 노드에 영향을 주면 안된다.
-
Partition tolerance 분할내성 = 시스템 부분간의 통신은 가끔 실패한다. 그래서 이걸 처리 할 수 있어야 한다.
현재의 시스템은 3가지 중에서 2가지를 선택하는 형식으로 되어있다.
분할 내성은 MSA에서 반드시 되어야 하는 부분이다.
그래서 CP 또는 AP 형태로 개발된다.
CP = 가용성 A를 희생한 경우
주문 서비스 인스턴스도 여러 개 있고
주문 데이터베이스도 여러개라고 해본다.
A,B,C 3개의 서비스 중 서비스 A에 장애가 났다. B,C 가 동작하면 일관성을 해친다.
그렇다면 A 의 장애에 맞게 B,C도 동작하지 말아야 할까
그렇지는 않다.
그래서 아래 AP 방식으로 개발한다.
AP = 일관성 C를 희생한 경우
서비스에 장애가 생겼을때 에러메세지를 리턴하지 않고 작업을 처리한다.
이렇게 하면 기능은 동작하지만 일관성을 잃게 된다.
추후 두 노드를 동기화 시켜준다.
TCC 트랜잭션 처리 방법 설명
- 잘 처리 되는 경우
주문 - 재고 - 결제 시스템 예시
-> 주문 서비스로 주문
Order service가 Stock service에 재고 -1연산을 수행한다.(Post)
Order service는 Payment service에 결제 연산을 수행한다.(Post)
Order service는 구매 주문을 생성한다.(Post)
Order service는 Stock service에 재고 -1을 확인하는 연산을 수행한다. (Put - payload { confirmed: true })
Order service는 Payment service에도 결제를 확인하는 연산을 수행한다. (Put - payload { confirmed: true })- Try 요청에서 서비스 장애 발생시
주문 서비스가 재고 서비스에 -1 연산을 한다. (POST)
주문 서비스는 결제 서비스에 결제 연산을 한다. (POST)
주문 서비스는 구매 주문을 생성하다 실패했다. - 장애 발생
주문 서비스는 재고 서비스에 -1 한 것을 지우는 연산을 한다. (DELETE)
주문 서비스는 결제 서비스에 결제를 취소하는 연산을 한다. (DELETE)- 잘 처리 되고 Confirm 연산에서 장애 발생하는 경우 - 결과적 일관성
현재는 처리가 되지 않았지만 화면에는 처리 되었다고 표시하고 나중에 처리한다.
예를 들어서 PG 사 장애로 결제가 안되었다고 주문 처리를 롤백하면 판매자는 판매를 못하게 된다.
현재는 처리하고 Confirm 요청을 큐, 로그 같은 파일에 담고 비동기로 처리한다.
Confirm 처리에서 오류가 난다면 계속 재시도 해서 처리한다.- 결과적 일관성 모델 구조
1. 주문 서비스가 재고 서비스에 -1 연산을 수행한다. (POST)
2. 주문 서비스가 결제 서비스에 결제 연산을 수행한다. (POST)
3. 주문 서비스가 구매 주문을 생성한다.
4. 주문 서비스가 재고 서비스에게 확정 요청을 보낸다. (PUT)
확정 연산에서는 DB 를 직접 업데이트 하지 않고 큐로 메세지를 보낸다.
재고 서비스가 큐로부터 메세지를 받아서 확정 처리한다.
5. 주문 서비스가 결제 서비스에게 확정 요청을 보낸다. (PUT)
확정 연산에서는 DB 를 바로 업데이트 하지 않고 큐로 메세지를 보낸다.
결제 서비스가 큐로부터 메세지를 받아서 확정 처리한다.MSA를 하는 이유 / 장점
-
확장성이 좋다.
- 새로운 도메인이나 기능 추가가 되었을때 모놀리틱에서는 전체 코드를 실행해서 테스트 해야한다.
- 전체 다른 코드에 대해서 의존관계는 없는지 문제가 없는지 살피며 개발해야한다.
- MSA 에서는 분리된 작은 양의 코드베이스로 개발 할 수 있어서 확장성이 좋다.
-
장애 발생시 전체 서비스가 다운되지 않는다.
- 모놀리틱 서비스에서는 1개가 장애가 발생하면 전체 시스템이 다운된다.
- MSA에서는 1개 인스턴스에 장애가 발생해도 다른 인스턴스가 작업을 할 수 있다.
- ex) 네이버 검색시 지도 서비스에 장애가 발생해도 지식인 서비스는 동작한다.
MSA 단점
-
일관성을 보장하기 어렵다.
- 분산된 서비스에서 장애가 발생하면 트랜잭션을 처리하는 것이 모놀리틱보다 어렵다.
-
버그 발생시 찾기가 어렵다.
- 모놀리틱은 1개의 코드베이스만 보면 된다.
- MSA 에서는 장애 발생시 로컬에 여러 인스턴스를 동시에 띄우고 찾는다던가 원인 지점을 찾기가 어렵다.
모놀리틱의 장점
-
트랜잭션 처리가 쉽다.
- MSA에서는 분산 트랜잭션을 다루기 어렵다.
- 모놀리틱에서는 같은 코드베이스에서 트랜잭션을 보장하기 쉽다.
-
버그 발생시 위치를 추적하는게 MSA보다 더 쉽다.
- 1개의 코드베이스에서 발생한 버그는 어디서 문제가 생겼는지 찾기 쉽다.
모놀리틱의 단점
- 1개 서비스 장애시 전체 서비스가 다운된다.
- 기능 확장시 모두가 같은 코드로 작업하기 때문에 확장이 쉽지 않다.
성능 튜닝
서버가 느릴때 할 수 있는 일
- 코드레벨에서는 n 제곱 = 이중 for 문으로 가는 로직을 Map 같은 자료형을 써서 n 으로 줄인다.
- 레디스 캐시를 활용해서 다른 api 에 요청을 보내는게 있다면 빠르게 만든다.
- DB 를 2번 갔다오는 연산이 있다면 1번만 갔다 오도록 한다.
- network 요청 , DB IO 연산에서 주로 많은 시간이 걸린다.
자바스크립트 성능 측정을 new Date로 하면 안되는 이유
- 일단 new Date() 연산도 시간이 걸린다.
- 실행 할때마다 늘 그 속도로 돌아가리라는 보장이 없다.
- 로컬에서 켰을때 나온 속도랑 실제 api가 돌아갈때 나오는 속도가 다르다.
- 엔진/시스템이 그때 그때 어떻게 간섭을 일으킬지 예측 할 수 없다.
- new Date()의 시간 단위도 문제다. 플랫폼마다 시간 단위 정확도가 다르다.
정확한 툴은 Benchmark.js 를 활용하는 것이다.
벤치마킹은 주어진 작업 실행 시간동안 측정한 결과를 보고 뭘 알수 있는지 없는지 파악하는게 기본이다.
꼬리물기 최적화 (TCO = Tail Call Optimization)
- es6 부터 지원하는 기능인데 함수 재귀 호출시 스택 프레임을 최적화 하는 것을 말한다.
재귀적으로 호출하는 함수를 잘못 호출하면 스택이 계속 쌓인다.
꼬리 호출 최적화를 사용하면 함수 호출시 이전 스택 프레임을 재사용한다.
속도도 빠르고 메모리도 덜 사용한다.하는 방법 : 함수 끝에서 return 문을 실행하도록 함수를 호출한다.
쿠버네티스
쿠버네티스를 쓰는 이유
컨테이너화된 서비스를 편리하게 관리하기 위해서 쓴다.
트래픽이 많으면 트래픽을 로드밸런싱해준다.
실패한 컨테이너를 다시시작, 교체. => 자동화된 복구를 해준다.
시크릿 값 구성, 관리가 좋다.
쿠버네티스 구조
쿠버네티스 마스터 - 노드 - 파드 - 컨테이너
파드, 서비스, 디플로이먼트 각각 설명
-
파드: 쿠버네티스에서 서비스 배포 단위가 된다.
-
볼륨: 컨테이너 안의 디스크 파일은 임시적이다. 볼륨은 컨테이너 사이에 파일을 공유해야할때 문제를 해결해줄 수 있다.
- 쿠버네티스에서 지원하는 볼륨의 예시: ConfigMap, Secret
-
네임스페이스: 동일한 물리 클러스터를 기반으로 한 가상의 클러스터
- 여러개의 네임스페이스를 나눠서 서비스를 운영 할 수도 있다.
-
데몬 셋: 데몬셋 은 모든(또는 일부) 노드가 파드의 사본을 실행하도록 한다.
노드가 클러스터에 추가되면 파드도 추가된다. 노드가 클러스터에서 제거되면 해당 파드는 가비지(garbage)로 수집된다. 데몬셋을 삭제하면 데몬셋이 생성한 파드들이 정리된다. -
스테이트풀 셋: 파드들의 순서, 고유성을 보장하는 역할을 한다.
- 스테이트풀 셋은 순차적인 배포, 스케일링이 필요한 애플리케이션에서 쓴다.
- 만약 순차적인 배포, 삭제, 스케일링이 필요 없다면 디플로이먼트/레플리카 셋을 쓰는 것이 더 적합 할 수 있다.
-
레플리카 셋: 파드 집합의 실행을 안정적으로 유지한다.
- 명시된 파드 개수에 대한 가용성을 보증한다.
-
디플로이먼트: 파드를 어떻게 배포할지에 대한 명세를 담고 있다.
- 예를 들어서 이미지는 어디서 가져올지
- 포트는 몇 번을 사용할건지
- configMap, Secret 변수는 뭘 사용할 건지
이런 내용을 담고 있다.
-
서비스: 서비스는 배포한 서비스를 외부로 노출 시키는 역할을 한다.
- 배포한 항목의 ip 주소를 얻을 수 있다.
- 클러스터 ip 를 얻을 수 있다.
-
로드밸런서: external-ip 를 얻을 수 있다.

-
인그레스: 클러스터 내의 서비스에 대한 외부 접근을 관리하는 API 오브젝트이며, 일반적으로 HTTP를 관리함.
인그레스는 부하 분산, SSL 종료, 명칭 기반의 가상 호스팅을 제공할 수 있다- 서비스를 구분해서 라우팅 해줄 수도 있다.
/order => order service
/payment => payment service
- 서비스를 구분해서 라우팅 해줄 수도 있다.
-
노드: 애플리케이션과 클라우도 워크플로우를 구동시키는 머신(VM, 물리 서버)이다.
- 노드는 쿠버네티스에서 워커 머신을 말하며 클러스터에 따라 가상 또는 물리 머신일 수 있다.
- 각 노드는 마스터에 의해 관리된다. 하나의 노드는 여러 개의 파드를 가질 수 있다.
- 쿠버네티스 마스터는 클러스터 내 노드를 통해서 파드에 대한 스케쥴링을 자동으로 처리한다.
-
쿠버네티스 마스터: 각 노드를 관리한다.
-
레이블: 레이블은 파트와 같은 오브젝트에 첨부된 키:값 쌍이다.
- 쿠버네티스의 리소스를 선택하는데 쓰인다.
-
셀렉터: selector 를 사용해서 사용자는 쿠버네티스 오브젝트를 식별 선택 할 수 있다.
- label 값으로 리소스를 선택한다.
쿠버네티스가 하지 않는 일
- 소스코드를 배포하거나 빌드하지는 않는다. CI/CD 는 Jenkins, Teamcity 같은 빌드 툴을 사용한다.
- 애플리케이션 레벨의 서비스는 제공하지 않는다.
- 로깅 솔루션을 제공하지는 않는다. 로깅 환경은 ELK 같은 스택을 활용해서 따로 구축해야 한다.
컨테이너 라이프 사이클 훅
컨테이너가 시작되거나 종료 될때 실행되도록 정의하는 동작
리액트 훅이 컴포넌트가 마운트 되었을때, 변경 사항 발생시 실행하도록 한다면
컨테이너 라이프사이클 훅은 컨테이너에 변동사항이 생겼을때 동작하도록 해줄 수 있다.
쿠버네티스의 가비지 컬렉터
더이상 소유자가 없는 오브젝트를 삭제한다.
- 일부 쿠버네티스 오브젝트는 다른 오브젝트의 소유자이다.
- ex) 레플리카 셋은 파드 집합의 소유자이다.
쿠버네티스 잡
실행하는 명령
쿠버네티스 오브젝트에 정의하고 쓴다.쿠버네티스 크론잡
지정된 시간에 실행하는 명령
예를 들어서 아래와 같은 명령을 실행 할 수 있습니다.
매일 오후 6시에 특정 파드를 실행하라Istio
istio 정의
MSA끼리 서로 통신할때 서비스들의 정보를 갖고 있고 프록시를 통해서 접속 할 수 있게 해준다.
프록시를 통해서 접속하면 서킷 브레이커를 직접 구현하지 않아도 된다.
댓글