Java FAQ
자바 프로그램 실행 과정
개발자가 자바 코드를 컴파일 한다. .
java 파일이 .class 파일로 변경된다.
자바 코드가 바이트 코드로 변경된 것이다.
컴파일 된 바이트 코드를 JVM 클래스 로더에 전달한다.
JVM의 클래스 로더가 동적 로딩을 통해서 필요한 클래스를 로딩해서 JVM 의 메모리에 올린다.
JVM의 실행 엔진이 바이트코드를 명령어 단위로 실행한다.
Java call by value , call by reference
call by value 는 값에 의한 호출이다.
함수에 값을 전달해서 다루는 것이 이에 해당한다.
int, long, byte, short, boolean 같은 primitive 타입으로 선언하고 값을 사용한다.
void hello(int a) {
a = 20; // 함수 안에서만 a를 20으로 변경한다.
}
void main() {
int a = 10;
hello(a);
print(a) // a는 그대로 10이다. 값에 의한 호출이기 때문이다.
}
call by reference 는 참조에 의한 호출이다.
주소 값을 전달해서 호출 하는 것을 말한다.
자바에서 primitive 타입을 제외한 다른 참조 타입들을 말한다.
class Ref {
public int thisField = 0;
void ref(Ref ref){
ref.thisField = 20;
}
}
class Main {
void main() {
Ref ref = new Ref();
ref.thisField = 30;
ref.ref(ref);
print(ref.thisField);
}
}Ref 클래스의 인스턴스를 전달했다.
받는 함수에서 intance의 변수 값을 변경했다.
이렇게 하면 Main 클래스에서 ref 인스턴스의 값을 확인 했을때 변경된 값이 나오게 된다.
String , StringBuilder , StringBuffer 차이
자바에서는 문자열을 다룰때 String, StringBuilder, StringBuffer를 제공하고 있다.
String 은 문자열 변수를 저장할때 사용한다.
StringBuilder 와 StringBuffer는 문자열 변수를 조작할 일이 많을때 쓴다.
"안녕하세요 " 라는 문자열을 String 에 저장했을때는 문자열 연산이 좋지 않다.
String a = "안녕하세요";
a.append(" fors"); // 이런 식으로 뒤에 덧붙여서 조작 할 수 없다.
a = "안녕하세요 fors" // string 은 이렇게 새로 할당해서 조작해야한다.
StringBuilder a = new StringBuilder();
a.append("안녕하세요");
a.append("fors"); // StringBuilder는 이렇게 덧붙여서 쓰는게 가능하다.
StringBuffer도 이렇게 쓸 수 있다.StringBuilder와 StringBuffer의 차이점은 Thread safe한지 아닌지이다.
StringBuffer는 Thread safe하다. StringBuilder는 그렇지 않다.
문자열 연산이 많고 Thread safe해야 한다면 StringBuffer를 사용하고 Thread safe할 필요가 없다면 StringBuilder를 사용한다.
가비지 컬렉터
자바에서 사용하지 않는 힙 영역의 메모리를 관리해주는 역할을 한다.
가비지 컬렉터는 언제 동작하는가?
가비지 컬렉터는 아래 조건이 충족되면 동작한다.
ㅇ OS로부터 할당받은 시스템의 메모리가 부족한 경우
ㅇ 관리하고 있는 힙에서 사용되는 메모리가 허용된 임계값을 초과한 경우
ㅇ 프로그래머가 직접 GC 를 사용한 경우 - 시스템 성능에 큰 영향을 주기 때문에 사용하지 않는게 좋다. - 관련 글 https://d2.naver.com/helloworld/1329
가비지 컬렉터를 이야기 할때는 stop-the-world 를 빼놓을 수 없다.
stop-the-world 는 GC 실행을 위해서 JVM 이 애플리케이션 실행을 멈추는 것이다.
애플리케이션은 GC 가 동작한 후에 이어서 동작한다.
GC 의 성능 튜닝은 stop-the-world 시간을 줄이려고 노력한다.
가비지 컬렉터는 어떻게 동작하는가?
GC 과정은 Mark and Sweep 이라고도 부른다.
Mark는 GC가 스택의 모든 변수, 접근 가능한(Reachable) 객체들을 스캔하면서 각각 어떤 객체를 참조하고 있는 지 찾는 과정이다.
이 mark 과정에서 stop-the-world가 발생한다.
Sweep 은 mark 과정이후에 mark 되어 있지 않은 객체를 힙에서 제거하는 과정이다.
더 자세히 알아보자면.
JVM의 Heap 영역은 Young, Old, Perm 영역으로 나뉜다.
각각의 영역에서 모두 GC가 일어난다. 그리고 Young, Old, Perm 영역에서 일어난 GC 는 부르는 이름도 다르다.
Young 영역 - 여기서 일어난 GC 는 Minor GC라고 부른다.
Young 영역의 특징 : 새롭게 생성된 객체가 여기 위치한다.
대부분의 객체가 금방 Unreachable 상태가 된다.
그래서 많은 객체들이 만들어지고 사라진다.
Old 영역 - 여기서 일어난 GC 는 Major GC라고 부른다.
Old 영역의 특징: Young 영역에서 Reachable 상태를 유지해서 살아남은 객체가 여기로 복사된다.
대부분 Young 영역보다 크게 할당한다. 크기가 큰 만큼 Young 영역보다 더 적은 GC 가 일어난다.
Perm 영역 - 여기서 일어난 GC는 Major GC 라고 부른다.
Perm 영역의 특징: Method area 라고도 부른다.
클래스와 메소드 정보처럼 자바 언어 레벨에서는 거의 사용되지 않는 영역이다.
여기서 말하는 Reachable 은 스택에서 힙영역의 객체를 참조할 수 있는지를 말한다.
Reachability = 자바는 가비지 객체를 판별하기 위해서 Reachability라는 개념을 사용한다.
어떤 객체에 유효한 참조가 있으면 reachable, 없으면 unreachable로 구별한다. unreachable 객체는 가비지로 간주한다.
Java 버전이 올라감에 따라서 GC 가 동작하는 알고리즘도 점점 더 개선되어 갔다.
Error Exception
Error 는 컴파일시 문법적인 오류, 런타임시 널포인트 참조 같은 오류를 말한다.
프로세스를 종료 시킬 수 있다.
Exception은 동작 중 예기치 않았던 이상 상태가 발생해서 영향을 받은 경우이다.
예를 들어서 "ㅁㅇㄹ" 같은 문자열을 Integer.parseInt() 하게 되면 Exception 이 발생한다.
Exception 의 종류
checked exception - 예외처리가 필수 - IOException, FileNotFoundException
checked Exception 은 컴파일 전에 IDE 에서 이미 표시된다.
예외를 처리해주지 않으면 컴파일 되지 않는다.
unchecked exception - 예외처리가 선택 - NullPointerException, IndexOutOfBoundException
unchecked exception 은 런타임에서 발생하는 exception 이다. 컴파일때 체크하지 않는다.
리플렉션
객체를 통해서 클래스의 정보를 분석하는 기법을 말한다.
객체를 통해서 해당 클래스의 메소드, 필드들을 알아내고 사용할 수 있다.
구체적인 클래스 타입을 몰라도 클래스의 메소드, 타입, 변수들을 접근 할 수 있게 해준다.
자바에서는 원래 구체적인 클래스 타입을 모른다면 메소드를 실행할 수 없다.
class Sub {
void hello(){
System.out.println("hello");
}
}
class Main {
public static void main(String[] args) {
Object sub = new Sub();
sub.hello(); // 이건 할 수 없는 일이다.
}
}
왜 필요할까
이렇게 Sub 클래스의 객체를 Object 타입의 변수에 저장한다면 변수 sub를 가지고 Sub 클래스의 변수, 함수에 접근 할 수 없다.
Object타입의 변수에 대입되고 있기 때문에 Object 클래스에 있는 함수, 변수들만 접근 할 수 있다.
그런데 자신이 만든 클래스인데 메소드와 타입을 모르는게 가능할까?
대표적인 경우는 Intlellij 의 자동완성 기능을 들 수 있다.
IDE에서는 ArrayList, Date... 등등 수많은 클래스에 대해서 인스턴스를 만들면 자동완성으로 필드와 메소드를 보여준다.
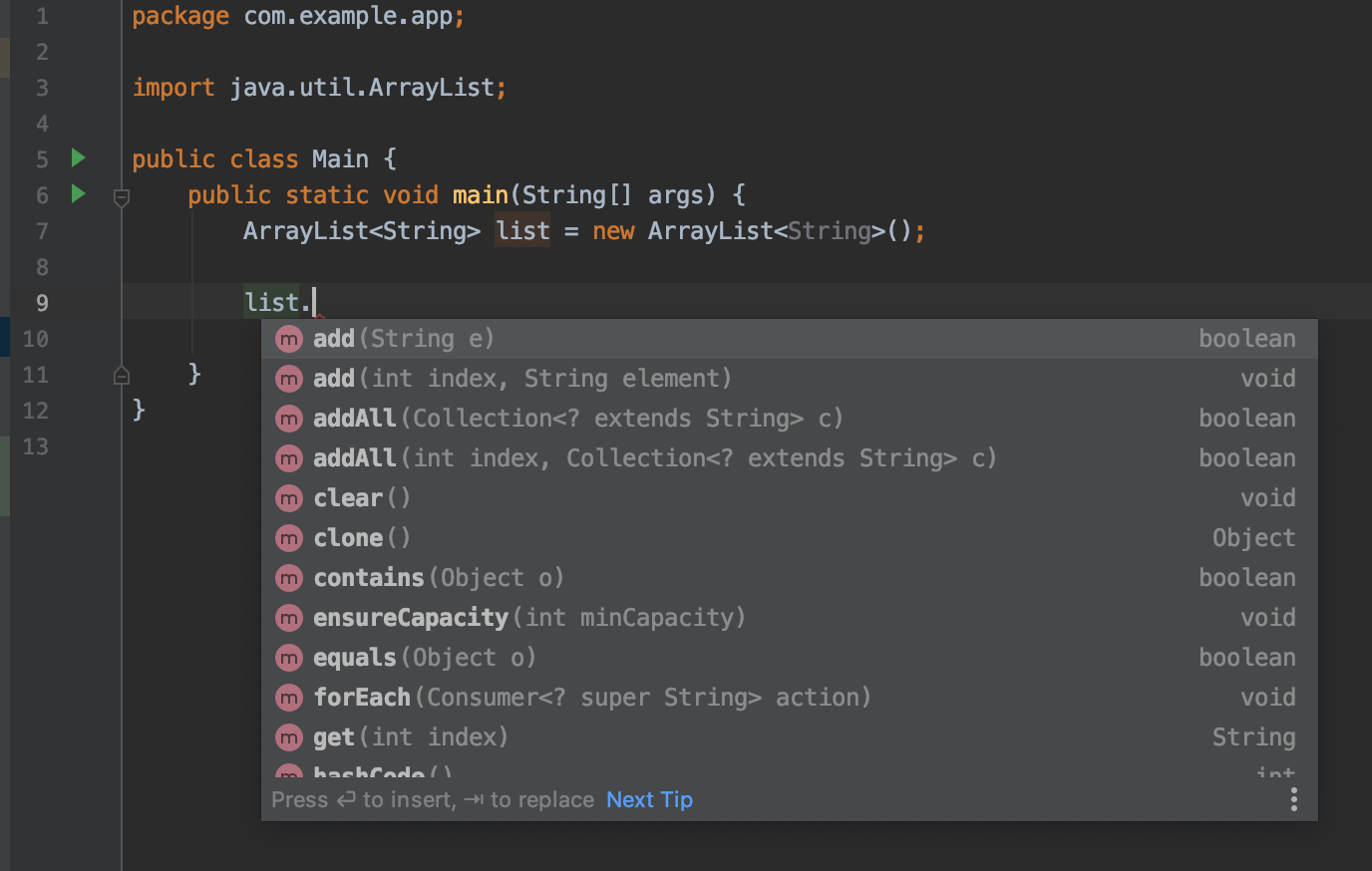
IDE 에서는 list 의 타입이 Arraylist인것을 리플렉션을 통해서 확인한다.
리플렉션을 사용하면 프로그램의 실행중에도 클래스 정보를 알아내는 것이 가능하다.
직접 만드는 클래스에 대해서 사용해보고 싶다면 Class 클래스를 활용하면 된다.
package com.example.app;
import java.lang.reflect.Method;
import java.util.ArrayList;
class ReflectThis {
long variable;
int value;
void hello() {
}
int sum(int a, int b) {
return a + b;
}
}
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
try {
Class reflectThis = Class.forName("com.example.app.ReflectThis");
Method methods[] = reflectThis.getDeclaredMethods();
for (int i = 0; i < methods.length; i++) {
System.out.println(methods[i].toString());
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}

출력문
Class.forName을 사용해서 클래스를 찾는다.
그리고 선언된 메소드들을 출력했다.
http https 차이
http 는 HyperText Transfer Protocol 의 줄임말이다.
웹에서 정보를 주고 받는 프로토콜이다.
웹 브라우저와 서버가 웹페이지 같은 자원을 주고 받는 통신 규약이다.
html 페이지는 텍스트이기 때문에 누군가 네트워크에서 신호를 가로챈다면 내용이 그대로 노출된다.
이런 보안상의 문제를 해결해주는 프로토콜이 https 이다.
https는 인터넷 상에서 정보를 암호화하는 SSL 프로토콜을 이용해서 웹 브라우저와 서버가 데이터를 주고받는 통신 규약이다.
https는 http 메시지를 암호화 하는 것이다.
https의 s 는 secure socket = 보안 통신망을 의미한다.
https의 동작 원리
하이퍼텍스트
https 는 대칭키와 공개키 암호화 방식으로 암호화를 한다
대칭키 암호화 방식은 아래 그림과 같다.

키가 되는 문자열을 사용해서 평문을 암호화 한다.
암호화에 사용한 키는 암호문을 해독할때도 사용한다.
이런 방식은 대칭키가 노출되면 굉장히 위험하다.
그리고 대칭키를 노출되지 않게 전달하는 것도 어렵다.
그래서 공개키 방식이 등장했다.
공개키 암호화 방식은 공개키를 통해서 암호화 한 내용은 비밀키를 사용해서만 해독할 수 있도록 하는 것이다.

공개키 방식은 A키로 암호화 하면 B키로 복호화 할 수 있다.
B키로 암호화 하면 A키로 복호화 할 수 있다.
이렇게 하면 암호화 하는 키를 공개 키로 지정하고 복호화 하는 키를 비밀키로 지정한다.
비밀키가 없는 사람은 암호문을 해독 할 수 없다.
SSL 인증서
인증서의 역할
클라이언트가 접속한 서버가 신뢰할 수 있는 서버임을 보장한다.
서버의 공개키를 클라이언트가 받을 수 있도록 한다.
SSL 인증서를 구하는 방법
CA (Certificate Authority) 역할을 할 수있는 민간 기업으로부터 구한다.
SSL 인증서에 들어있는 내용
SSL 인증서에는
1. 서비스 정보 = 인증서를 발급해준 CA, 서비스의 도메인 등
2. 공개키 = 공개키의 내용, 공개키의 암호화 방법
인증서의 내용은 2가지로 구분 할 수 있다.
1. 클라이언트가 접속한 서버가 의도한 서버가 맞는지에 대한 내용
2. 통신에 사용할 공개키와 그 키의 암호화 방법
SSL 을 통해서 동작하는 과정
|
Handshake 단계 클라이언트는 서버에게 랜덤데이터, 지원하는 암호화 방식들, 세션 id 를 보낸다.
서버는 클라이언트가 보내준 암호화 방식 중에서 암호화 방식을 선택한다. 서버도 랜덤 데이터를 보낸다. 서버는 인증서도 보낸다.
클라이언트는 가지고 있는 CA 리스트에 있는 인증서인지 확인한다. 가지고 있는 CA 의 공개키를 사용해서 인증서를 복호화 한다. 복호화 했다면 인증서가 정상인 것으로 받아들이고 서버를 신뢰한다.
클라이언트는 서버의 랜덤 데이터와 클라이언트의 랜덤데이터를 조합해서 pre master secret 이라는 키를 생성한다. 이 키는 세션에서 주고 받는 데이터를 암호화하기 위해서 사용된다.
pre master secret 은 서버의 인증서에 들어있는 공개키를 사용해서 암호화 한다. 그리고 서버에서는 pre master secret 키를 복호화 해서 키를 얻는다.
서버와 클라이언트는 pre master secret 값을 master secret 값으로 만든다. master secret 값은 세션 키를 생성한다. 세션 키를 사용해서 서버와 클라이언트는 데이터를 대칭키 방식으로 암호화 해서 주고 받는다.
여기까지 핸드쉐이크 단계가 종료된다.
|
|
세션 세션은 실제로 서버와 클라이언트가 데이터를 주고 받는 단계이다. 데이터를 전송하기 전에는 세션 키 값을 사용해서 대칭키 방식으로 암호화 한다.
그냥 공개키를 사용하면 되겠지만 이렇게 대칭키를 사용하는 이유는 공개키가 많은 컴퓨팅 파워를 쓰기 때문이다. 데이터를 주고 받을 때는 대칭키를 사용한다.
|
|
세션 종료 데이터 전송이 끝나면 SSL 통신이 끝났음을 알린다. 통신에 사용한 대칭키인 세션키는 폐기한다. |
자바 접근제한자 차이
private - 클래스 안에서만 접근 가능
protected - 같은 패키지 안에 있는 객체, 상속관계의 객체들만 허용
default - 같은 패키지에 있는 객체들 허용
public - 모든 접근을 허용한다.
자바 final 키워드
final 은 해당 변수를 상수로 만든다.
클래스에 final을 쓰면 상속 할 수 없다.
메소드에 final 을 쓰면 오버라이드 할 수 없다.
Static 키워드
static 을 사용하면 클래스의 모든 인스턴스가 공유하는 메소드와 변수가 된다.
객체의 직렬화
객체를 json 같은 통신하기 좋은 형태로 바꾸는 것을 직렬화라고 한다.
반대로 json을 객체로 만드는 것을 역직렬화라고 부른다.
io 패키지 안에 있는 Serializable 인터페이스를 상속받으면 직렬화가 가능한 클래스로 변경 할 수 있다.
직렬화 하고자 하는 클래스에 직렬화가 안되는 객체가 포함되어 있을 경우 transient 키워드를 사용하면 직렬화에서 제외시킬 수 있다.
래퍼 클래스
기본 자료형으로 표현된 데이터를 참조 자료형으로 만들어야 할 결우 래퍼클래스를 사용한다.
Integer, Short, Long, Boolean 같은 클래스가 여기 해당한다.
스레드 동기화, 데드락
2개 이상의 스레드가 공유 자원에 접근해서 값을 변경하려고 할 때, 동기화를 적용하지 않으면 값이 잘못 변경 될 수도 있다.
이것을 레이스 컨디션이라고 부르기도 한다. 동기화가 필요하다.
공유 변수에 synchronized 키워드를 사용해서 동기화 하거나 블록을 설정해서 하나의 쓰레드가 공유자원을 점유 할 경우 다른 스레드가 대기 하도록 할 수 있다.
데드락은 두 스레드가 모두 대기상태에 계속 머무르는 것을 말한다.
예를 들어서.
a 스레드는 foo 라는 공유 변수에 락을 걸어두고 작업한다.
b 스레드는 bar 라는 공유 변수에 락을 걸어두고 작업한다.
a 스레드에서 bar 가 필요한 코드를 만났다. 그러나 bar는 b스레드가 선점하고 있으므로 a스레드는 대기 상태가 된다.
b 스레드도 foo 가 필요한 코드를 만났다. 그러나 foo 는 a 스레드가 선점하고 있으므로 b스레드도 대기 상태가 된다.
이렇게 계속 대기 상태가 되는 것을 데드락이라고 부른다.
CORS(Cross Origin Resource Sharing)
도메인 또는 포트가 다른 서버의 자원을 요청하는 것을 말한다.
아래 그림 같은 문제를 말한다.

해결하는 방법은 아래와 같다.
1. 같은 도메인, 같은 포트를 사용한다.
2. 서버에서 Access-Control-Allow-Origin response 헤더를 추가한다.
Vector 와 Arraylist 의 차이
Vector - 동기식으로 동작한다.
한 스레드가 작업 중이면 다른 스레드가 작업할 수 없다.
Arraylist - 비동기식으로 동작한다.
여러 스레드가 동시에 작업할 수 있다.
자바의 메모리 영역
메소드 - 바이트 코드, 전역변수, static 변수
스택 - 매개변수, 지역변수, primitive 타입 변수들이 할당 된다. 컴파일시에 메모리에 할당된다.
힙 - 런타임에 동적으로 할당되고 가비지 컬렉터에 의해서 제거되는 영역. new로 생성하는 객체들이 담긴다.
오버로딩, 오버라이딩 차이
오버로딩은 메소드의 이름은 같고 매개변수를 달리 함으로써 여러개의 메소드를 만드는것.
오버라이딩은 상위 클래스의 메소드를 하위 클래스에서 재정의해서 다른 기능을 하도록 만드는 것
추상 클래스와 인터페이스의 차이
추상 클래스 - 추상클래스는 클래스 안에 추상 메소드가 하나 이상 포함되거나 abstract로 정의된 경우를 말한다.
상속 받는 클래스에서 추상 메소드를 구현 하도록 강제한다.
extends 를 통해서 기능을 이용하고 확장하도록 하는 클래스다.
인터페이스 - 메소드를 가진다. 하위 클래스에서 반드시 구현해야 한다.
interface In {
void hello();
}
abstract class Abs {
void hello(){
int a = 2;
int c = 2;
}
}인터페이스는 함수의 몸체를 가질 수 없다.
추상 클래스는 함수의 몸체가 있을 수 있다.
interface In {
void hello();
}
abstract class Abs {
int anInt;
void hello(){
int a = 2;
int c = 2;
}
}인터페이스는 변수를 가질 수 없다.
추상 클래스는 변수도 가질 수 있다.
비슷한 이 두 가지가 존재하는 이유는 자바가 다중 상속을 지원하지 않기 때문이다.
추상 클래스는 클래스를 상속 받아서 기능을 이용하고 확장하는 데 목적이 있다.
인터페이스는 다중 상속, 함수 구현의 강제에 목적이 있다.
Arraylist , Linkedlist 차이
arraylist 는 인덱스를 가진다.
탐색에 유리하다.
linkedlist 는 각 원소들이 자신의 이전 위치를 가지고 있다.
삽입 삭제에 유리하다.
해시
데이터 삽입, 삭제시 기존 데이터와 연관된 고유 값을 생성해서 인덱스로 사용하는 방법
검색 속도가 빠르다.
DB 에서 뷰는 무엇인가
뷰는 다른 테이블을 바탕으로 만들어진 가상의 테이블을 의미한다.
뷰는 실제로 데이터를 저장하지는 않는다.
그러나 사용자는 실제로 데이터가 존재하는 테이블과 동일하게 뷰를 조작 할 수 있다.
뷰 생성 쿼리 예제
CREATE VIEW WORK_VIEW
AS SELECT Fname, Lname, Pname, Hours
FROM EMPLOYEE, PROJECT, WORKS_ON
WHERE Ssn=Essn AND Pno=Pnumber;
CREATE VIEW DEPT_VIEW(Dept_name, No_of_emps, Total_sal)
AS SELECT Dname, COUNT(*), SUM(Salary)
FROM DEPARTMENT, EMPLOYEE
WHERE Dnumber=Dno
GROUP BY Dname;
SELECT * FROM WORK_VIEW;
SELECT * FROM DEPT_VIEW;
뷰를 생성 했을때의 장점
속도 향상 - 쿼리문이 돌지 않고 만들어진 뷰 테이블에서 가져온다.
사용 편의 - 뷰 테이블을 만들어두고 가져오기 때문에 사용이 편리하다.
보안 - 뷰를 통해서 접근하기 때문에 나타나지 않는 데이터를 보호 할 수 있다.뷰의 단점
뷰는 삽입 삭제 갱신에 제약이 있다.
독자적인 인덱스를 가질 수는 없다.
DB에서 인덱스는 무엇인가
인덱스는 탐색 속도를 향상시키기 위해서 사용한다.
인덱스는 키 - 컬럼 순으로 정렬되어 있다.
특정 값을 찾다가 해당 범위를 넘어서는 값을 만나면 멈춘다.
인덱스의 원리
컬럼에 인덱스를 주면 Table 생성시 만들어진 MYD, MYI, FRM 파일 중에서 MYI 파일에 해당 컬럼을 색인화해서 저장한다.
사용자가 index 가 되어 있는 컬럼에 select 쿼리를 하면 테이블을 검색하는게 아니라 빠른 tree로 정리해둔 MYI 파일의 내용을 검색한다.
찾고자 하는 값이 브랜치 왼쪽보다 작거나 같으면 왼쪽.
더 크다면 오른쪽으로 간다.
이렇게 트리를 탐색하면서 찾고자 하는 값이 있는지 탐색한다.
index를 사용하지 않는 select 쿼리라면 DB를 full scan 해서 검색한다.
-> 일반적으로는 이렇게 B-tree 를 사용한다.
메모리 기반의 DB에서는 Hash index 를 사용하기도 한다.
hash 인덱스는 컬럼 값으로 해시 값을 계산해서 인덱싱한다.
값을 변형해서 인덱싱하면 값의 일부만 검색하고자 할때는 쓸 수 없다.
인덱스의 장점
키 값을 기초로 테이블에서 검색과 정렬 속도를 올린다.
필드 중에는 데이터 형식 때문에 인덱스 될 수 없는 필드도 있다.
인덱스의 단점
인덱스를 만들면 .mdb 파일의 크기가 늘어난다.
인덱스 된 필드에서 update delete insert 할때 성능이 떨어진다.
인덱스의 종류
ㅇ고유 인덱스
고유 인덱스는 유일한 값을 갖는 컬럼에 대해서 생성하는 인덱스를 말한다.
SQL> CREATE UNIQUE INDEX idx_ukempno_emp ON emp(empno);UNIQUE 키워드를 사용해서 만든다.
부분 인덱스
성능은 향상 시키고 싶은데 용량 소비율은 최소화 할때 사용한다.
Field 전체보다 일부의 데이터만 인덱싱한다.
멀티 컬럼 인덱스
왜 모든 필드에 인덱스를 걸지 않는가
인덱스가 걸려있는 필드가 많아지면 insert, update, delete 연산의 성능이 저하된다.
더불어 db가 차지하는 용량도 늘어난다.
데이터베이스 JOIN 문
데이터베이스의 조인문은 두 개 이상의 테이블을 조회 한 결과를 합해서 하나의 결과를 얻고 싶을때 사용한다.
조인의 종류
Inner Join - 내부 조인 = 두 테이블에서 조건을 만족하는 행만 조회가 된다.
외부 조인인 Left Right 조인과 같지만 차이점은 where 절을 사용 할 수 있다.
Inner join 은 조인하고자 하는 두 개의 테이블에서 공통된 요소를 통해서 결합하는 조인 방식이다.
SELECT table1.col1, table1.col2, ..., table2.col1, table2.col2, ...
FROM table1 [table1의 별칭]
JOIN table2 [table2의 별칭] ON table1.col1 = table2.col2
Outer Join - 아우터 조인은 두 테이블의 공통 영역을 포함해서 한 쪽 테이블의 다른 데이터를 포함하는 조인 방식이다.
두 테이블간의 공통된 데이터가 없으면 이너조인은 데이터를 포함하지 못한다.
이렇때 데이터를 함께 가져오기 위해서 아우터 조인을 사용한다.
outer join 에는 left outer join, right outer join, full outer join 이 있다.
// left outer join
// select 부분의 앞쪽 테이블을 가져온다. = A 테이블 전체 + A 테이블과 B테이블의 교집합
select employee.empName, department.deptName
from employee
left outer join department on employee.deptNo = department.deptNo
// right outer join
// select 부분의 뒤쪽 테이블을 가져온다. = B 테이블 전체 + A 테이블과 B테이블의 교집합
select employee.empName, department.deptName
from employee
right outer join department on employee.deptNo = department.deptNo
// fuill outer join
// A 와 B 테이블의 합집합을 가져온다.
select employee.empName, department.deptName
from employee
full outer join department on employee.deptNo = department.deptNo
데이터베이스의 이상현상
릴레이션에서 일부 속성들의 종속으로인해 데이터 중복이 발생하는 것
데이터베이스를 설계할 때 가장 중요한 것
무결성을 보장해야 한다.
무결성에는 아래 5가지가 있다.
1. 널 무결성 - 릴레이션의 특정 속성 값이 null이 될 수 없도록 하는 규정
2. 고유 무결성 - 릴레이션의 특정 속성에 대해서 각 튜플이 갖는 값이 서로 달라야 한다.
3. 참조 무결성 - 외래키 값은 null 이거나 참조 릴레이션의 기본키 값과 동일해야 한다는 규정
- 릴레이션은 참조 할 수 없는 외래키 값을 가질 수 없다.
4. 도메인 무결성 - 특정 속성의 값이 그 속성이 정의된 도메인에 속한 값이어야 한다.
- 다른 테이블에 있을 값을 엉뚱한 테이블에 놓으면 안된다.
5. 키 무결성 - 하나의 테이블에는 적어도 하나의 키가 존재해야 한다.
이진 탐색 트리
https://ratsgo.github.io/data%20structure&algorithm/2017/10/22/bst/
이진탐색트리(Binary Search Tree) · ratsgo's blog
이번 글에서는 자료구조의 일종인 이진탐색트리(Binary Search Tree)에 대해 살펴보도록 하겠습니다. 이 글은 고려대 김선욱 교수님, 그리고 역시 같은 대학의 김황남 교수님 강의와 위키피디아를 정리하였음을 먼저 밝힙니다. 파이썬 코드는 이곳을 기본으로 하되 중위순회 등 요소를 제가 추가하였습니다. 그럼 시작하겠습니다. 이진탐색트리란 이진탐색(binary search)과 연결리스트(linked list)를 결합한 자료구조의 일종입니다. 이진탐색의
ratsgo.github.io
TCP UDP 통신의 차이
TCP, UDP 프로토콜은 전송계층에서 동작하는 프로토콜이다.
TCP - Transmission Control Protocol
UDP - User Datagram Protocol
| TCP | UDP |
| 연결 지향형 프로토콜 | 비 연결 지향형 프로토콜 |
| 바이트 스트림을 통한 연결 | |
| 혼잡제어, 흐름 제어 | |
| 순서 보장, 상대적으로 느림 | |
| 신뢰성있는 데이터 전송, 안정적 | 데이터 전송을 보장하지 않는다. |
| TCP 패킷 : 세그먼트 | UDP 패킷: 데이터 그램 |
| Http , 전자우편, 파일 전송에서 사용한다. | DNS, 실시간 동영상 서비스에서 사용한다. |
테스트 코드 작성시 레이어 나누기
MSA에서 공유 자원을 관리 하는 방법
MSA 통신에서 고정 아이피를 갖는가. 통신 주소 관리
MSA를 사용할때 중간에 끊기면 트랜잭션을 어떻게 보장할까
방법 1. 처음부터 트랜잭션으로 묶을 필요가 없도록 서비스를 디자인한다. - 이상적인 경우
방법 2. 보상 트랜잭션을 사용한다.
예를 들어서 MSA로 상품쪽 서비스와 결제쪽 서비스가 나눠져 있다고 해보자.
이 때 상품 쪽 서비스에서는 상품의 재고를 1개 감소 시키는 API를 제공했다고 하면
이에 대한 보상 트랜잭션으로 상품의 재고를 1개 증가 시키는 API를 제공하는 것이다.
결제가 실패하는 경우 이런 보상 트랜잭션을 호출하라는 것이다.
방법 3. 연산의 일부를 큐나 로그 파일에 큐잉해서 나중에 재시도 할 수 있다.
방법 4. 전체 작업 중지하기 - 보상 트랜잭션 발생 시키기(연산을 롤백한다)
단점 : 보상트랜잭션이 실패하면 어떨까
보상 트랜잭션의 실패에 따른 처리를 또 구현해야 한다.
방법 5. 분산 트랜잭션
하부 시스템에서 수행되는 다양한 트랜잭션을 통제하려고
트랜잭션 관리자라는 전체적인 통제 프로세스를 사용해서 트랜잭션 내부의 여러 트랜잭션을 확장하려고 시도한다.
분산 트랜잭션의 처리 방법
2단계 커밋 사용하기
MSA 구조의 장점 단점
장점:
1. 스케일 업이 쉽게 가능하다.
2. 장애 발생시 전체 서비스가 다운되지는 않는다.
단점:
1. 모놀리틱 서비스보다 관리에 신경써야 할 부분이 더 많다.
모놀리틱의 장점:
1. 마이크로 서비스 보다 배포 운영하기는 더 쉽다.
모놀리틱의 단점:
1. 장애 발생시 그대로 전체 서비스가 다운된다.
2. 스케일업에 많은 비용이 든다. - 인스턴스 자체의 성능을 높게 만들어야 한다.
Blocking IO 와 NonBlocking IO의 차이
블로킹 io는 io가 발생했을때 스레드가 그 처리를 기다린다. 스레드가 io를 마칠때까지 멈춘다
Nonblocking io는 polling , callback 등을 활용해서 io가 발생했을때 스레드가 작업을 기다리며 멈추지 않고 다음 작업을 처리한다
처리후 callback , polling 을 받아서 처리한다
Nodejs 의 비동기 처리 방식
Nodejs가 싱글스레드로 많은 요청을 처리 할 수 있는 이유
Nodejs는 다른 자바 같은 언어와 다르게 싱글스레드로 동작한다.
싱글 스레드는 멀티 스레드 언어보다 비효율적이지 않을까 생각 할 수 있다.
차이를 비교해본다
자바
1. 클라이언트가 서버에게 요청을 보낸다.
2. 웹 서버는 내부적으로 제한된 스레드 풀을 관리하고 클라이언트의 요청에 서비스를 제공한다.
3. 웹 서버는 무한루프에 있으며 클라이언트의 요청을 기다리는 중이다.
4. 웹 서버는 요청을 받아들인다.
웹 서버는 하나의 요청을 가져온다.
스레드 풀로부터 하나의 스레드에 가져온다.
이 스레드에 요청이 할당된다.
이 스레드가 요청을 읽고 처리한다.
이 스레드는 준비된 응답을 다시 웹 서버에게 보낸다.
웹 서버는 이 응답을 클라이언트에게 보낸다.
특징 :
서버는 무한루프에서 기다린다.
클라이언트의 요청이 오면 스레드를 하나 할당한다.
그 스레드가 요청을 읽고 처리한다.
스레드는 응답을 웹서버에게 보낸다.
웹서버는 응답을 클라이언트에게 보낸다.
만약 엄청 많은 요청이 Blocking io 를 요구하면
스레드 풀의 수많은 스레드는 응답 준비중이다.
나머지 클라이언트 요청은 더 오랜 시간을 기다리게 된다.
단점 - 점점 더 많은 동시에 발생하는 클라이언트의 요청을 처리하기 어렵다.
동시에 발생하는 클라이언트의 요청이 증가할 때, 많은 스레드를 이용해야 하기 때문에 많은 메모리를 쓰게 된다.
때때로 클라이언트의 요청은 사용 가능한 스레드가 요청을 처리할 때까지 기다려야 한다.
노드
1. 클라이언트가 서버에게 요청을 보낸다.
2. 웹 서버는 내부적으로 제한된 스레드 풀을 관리하고 클라이언트의 요청에 서비스를 제공한다.
3. 웹 서버는 무한루프에 있으며 클라이언트의 요청을 기다리는 중이다.
4. 웹 서버는 요청을 받아들인다.
웹 서버는 하나의 요청을 가져온다.
스레드 풀로부터 하나의 스레드에 가져온다.
이 스레드에 요청이 할당된다.
이 스레드가 요청을 읽고 처리한다.
이 스레드는 준비된 응답을 다시 웹 서버에게 보낸다.
웹 서버는 이 응답을 클라이언트에게 보낸다.
특징 :
서버는 무한루프에서 기다린다.
클라이언트의 요청이 오면 스레드를 하나 할당한다.
그 스레드가 요청을 읽고 처리한다.
스레드는 응답을 웹서버에게 보낸다.
웹서버는 응답을 클라이언트에게 보낸다.
만약 엄청 많은 요청이 Blocking io 를 요구하면
스레드 풀의 수많은 스레드는 응답 준비중이다.
나머지 클라이언트 요청은 더 오랜 시간을 기다리게 된다.
단점 - 점점 더 많은 동시에 발생하는 클라이언트의 요청을 처리하기 어렵다.
동시에 발생하는 클라이언트의 요청이 증가할 때, 많은 스레드를 이용해야 하기 때문에 많은 메모리를 쓰게 된다.
때때로 클라이언트의 요청은 사용 가능한 스레드가 요청을 처리할 때까지 기다려야 한다. 1. 클라이언트가 웹 서버에게 요청을 보낸다.
Nodejs 의 웹서버는 내부적으로 제한된 스레드 풀을 관리해서 클라이언트의 요청에 서비스를 제공한다.
Nodejs 의 웹서버는 클라이언트의 요청을 받아들이고, 큐 안에 배치한다.
이 큐를 이벤트 큐라고 부른다.
Nodejs의 웹서버는 내부적으로 이벤트 루프라고 불리는 컴포넌트를 가진다.
이벤트 루프라는 이름의 유래는 요청을 받아들이고 처리하는 것이 무한루프를 사용하기 때문이다.
이벤트 루프는 싱글 스레드를 사용한다.
이벤트 루프는 이벤트 큐에 배치된 클라이언트의 요청을 확인한다.
만약 없다면 무한히 대기한다.
있다면 이벤트 큐에 배치된 클라이언트의 요청을 가져온다.
클라이언트 요청을 처리한다.
만약 클라이언트 요청이 Blocking io 작업이 없다면, 모든 처리는 응답을 준비하고 클라이언트에게 보낸다.
만약 클라이언트 요청이 Blocking io 작업이 있다면 스레드 풀에서 사용 가능한 스레드를 확인한다.
특징 :
이벤트 큐, 이벤트 루프가 핵심이다.
큐 + 함수 앱처럼 이벤트 큐에 요청이 들어온다.
그리고 싱글 스레드인 이벤트 루프가 큐에서 요청을 받아서 처리한다.
많은 요청을 처리하는게 쉽다.
동시에 발생하는 클라이언트의 요청이 증가할때 이벤트 루프를 사용하기 때문에 많은 스레드를 쓰지 않는다.
멀티 스레드 방식보다 스레드를 덜 쓰기 때문에 메모리, 자원 소모가 적다.
단점: 싱글 스레드가 큐에서 꺼낸 일이 만약 큰 일이라면 좋지 않다.
큐에서 꺼낸 일이 CPU연산을 많이 쓴다면 그걸 처리하느라 시간이 오래 걸린다.
그러면 큐에 있는 다음 메세지를 꺼내는데 오랜 시간이 걸린다.
멀티 스레드였다면 오래 걸리는 일이 동시 진행 될 수 있다.
| 멀티 스레드 기반 - ex) 자바 | 싱글스레드 이벤트 루프 - Nodejs |
Nonblocking IO 의 장점
RxJava 의 특징
RxJava 의 장점
컴파일언어가 가지는 장점
SQS, Service Bus 큐를 사용했을때 장점
자바스크립트 클로저